Rebasing
Suppose that you create a branch "mywork" on a remote-tracking branch "origin".
$ git checkout -b mywork origin
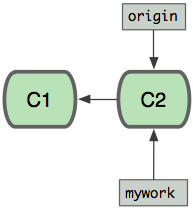
Now you do some work, creating two new commits.
$ vi file.txt
$ git commit
$ vi otherfile.txt
$ git commit
...
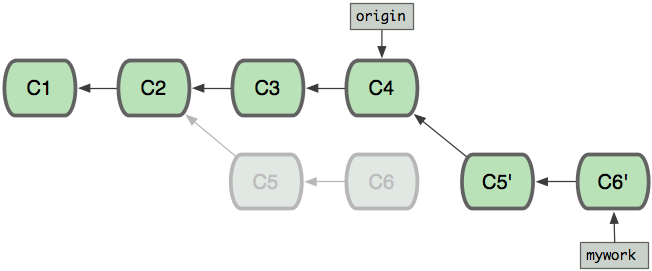
Meanwhile, someone else does some work creating two new commits on the origin branch too. This means both 'origin' and 'mywork' has advanced, which means the work has diverged.
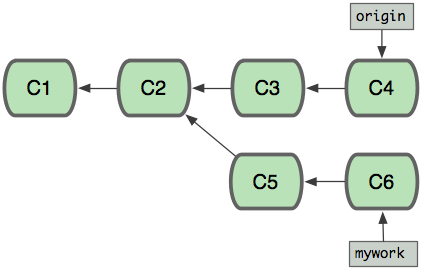
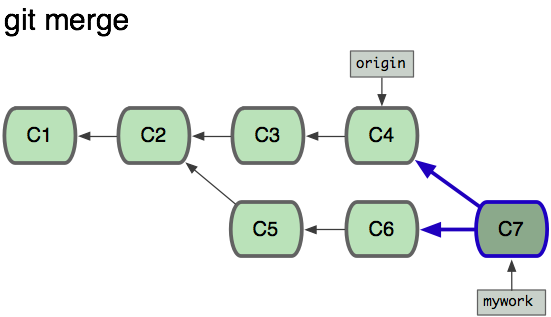
At this point, you could use "pull" to merge your changes back in; the result would create a new merge commit, like this:
However, if you prefer to keep the history in mywork a simple series of commits without any merges, you may instead choose to use git rebase:
$ git checkout mywork
$ git rebase origin
This will remove each of your commits from mywork, temporarily saving them as patches (in a directory named ".git/rebase"), update mywork to point at the latest version of origin, then apply each of the saved patches to the new mywork.
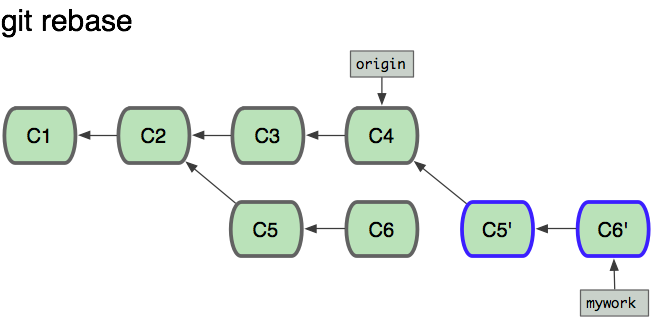
Once the ref ('mywork') is updated to point to the newly created commit objects, your older commits will be abandoned. They will likely be removed if you run a pruning garbage collection. (see git gc)
So now we can look at the difference in our history between running a merge and running a rebase:
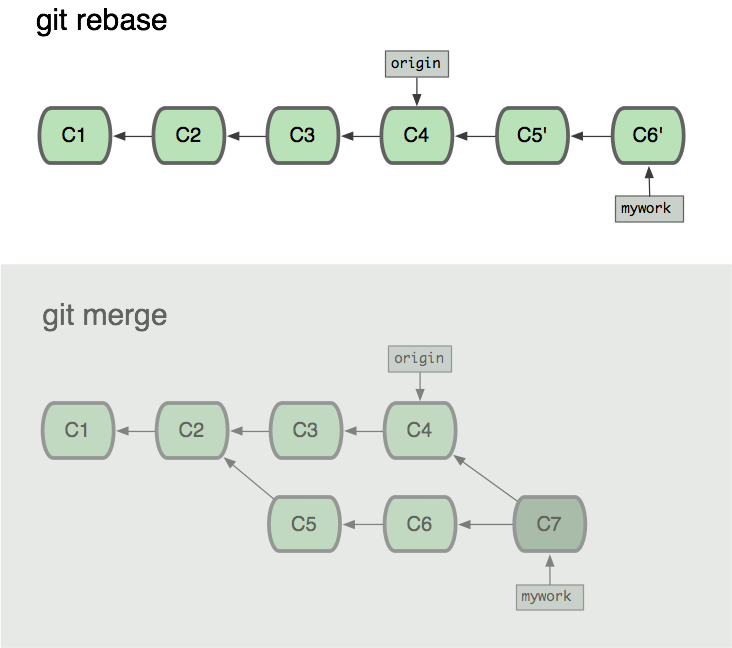
In the process of the rebase, it may discover conflicts. In that case it will stop and allow you to fix the conflicts; after fixing conflicts, use "git-add" to update the index with those contents, and then, instead of running git-commit, just run
$ git rebase --continue
and git will continue applying the rest of the patches.
At any point you may use the --abort option to abort this process and
return mywork to the state it had before you started the rebase:
$ git rebase --abort

